引言
作为没有接受过系统性计算机科学、人工智能教育的学生,我对 AI 的最初印象来自科普视频中提到的”深度学习算法””语言模型”这些词,听起来很酷,但也觉得很遥远。直到 2022 年 10 月首次使用 ChatGPT,才对”人工智能”有了实感。
后来因为好奇,参阅了一些介绍AI的资料,比如漫士沉思录的“彻底理解AI”系列,飞天闪客的AI入门、AI百问系列,使用了一些AI产品
- Web Chat型:ChatGPT,Gemini,Claude,Deepseek,Kimi,Qwen
- 本地 Agent 型:Claude Code,OpenCode
慢慢发现:AI 并没有那么神秘,它的基本原理和工程架构完全可以被理解。当然,这并不意味着我能从零开始训练出一个大模型——知识还是硬件都不足——只是想弄明白,AI 的工作原理是什么。
这篇文章用来记录我理解的过程。我会把学到的东西用自己的话写下来,尽量不用复杂的术语。因为我并非专业,所以理解肯定有很多不严谨的地方,但它可能恰好适合那些和我一样、没有太多技术背景但想了解 AI 的朋友——比如对科技好奇的普通人。
我不断地往本篇文章里添加新的笔记。如果你发现哪里写错了,或者有更通俗的解释,也欢迎告诉我。
Chapter 1:基础模型
训练与推理
训练过程就是寻找一个聪明的函数,推理过程就是将自变量(输入内容)代入函数(推理)得到因变量(输出)。
| 维度 | 训练阶段 | 推理阶段 |
|---|---|---|
| 本质 | 参数学习 通过海量数据进行机器学习,不断更新模型权重,得到一个函数。 |
参数应用 根据训练好的权重进行计算,处理输入内容,生成输出。 |
| 计算特性 | 需要极高算力(大量GPU),涉及梯度计算。 | 相对轻量,除了纯GPU方案外,还可以CPU、GPU混合推理运行,追求低延迟、高吞吐。 |
| 模型状态 | 模型参数随着训练而改变 | 模型参数处于冻结状态,保持不变 |
| 数据依赖 | 需要大规模标注数据集 | 依赖用户提示词(+ Prompt) |
每次和AI对话只是调用已经训练好的模型进行推理,模型本身不会因为对话而进化。所以那种“每次对话都在让AI变聪明”的说法是不准确的,真正的“进化”只发生在训练阶段。
AI 是如何“思考”
现在的模型本质还是概率模型,它并不能真正的思考,只是预测下一个Token。
训练的具体数学过程(梯度下降、回归算法等)超出了本文范围,读者如果感兴趣可以看引言中推荐的视频。下面重点解释推理阶段”思考”的核心机制:
- Token:语言模型处理自然语言的基本单位,可以直观的理解为“字”或“词”。不同模型的“分词器(Tokenizer)”不尽相同,但大致遵循以下规则:英文按子词拆分,可能被划分为多个 Token(如 “unhappy” → “un” + “happy”), 1 英文字符 ≈ 0.3 Token;汉语按字词拆分,1 中文字符 ≈ 0.6 Token。
- 概率预测:AI 在写完回复之前,不知道它要输出什么内容;它基于”自回归算法”——像玩词语接龙,用已经生成的部分来预测接下来该生成什么——推测”下一个 Token 可能是什么”。
- 温度 (Temperature):调节概率分布的“集中程度”;低温更有确定性,高温更有创造力。
- 思维链 (Chain of Thought):这种策略会引导模型将复杂问题分解为连续任务,降低单步推理难度,提升整体准确率。
推理的内部过程
模型内部是一层层的矩阵乘法,Token 向量穿行其中。Attention 决定哪些信息重要,而它的计算中间结果可以被缓存下来反复利用。
从 Token 到向量
每个 Token 进入模型后,首先被映射为一个高维向量(Embedding)。这个向量就是模型”理解”这个 Token 的数学表示——意思相近的词,它们的向量在空间中靠得更近。
层层变换
向量随后穿过多个 Transformer 层。每一层做两件事:
- 注意力(Attention):让当前 Token 看到其他所有 Token,决定哪些信息重要
- 前馈(Feed-Forward):对每个 Token 独立做一次非线性变换——可以理解为把注意力提取到的信息再加工提炼一次
几十甚至上百层后,最终的向量用来预测下一个 Token。
Attention 的计算
假设大模型已经生成了前三个 Token:”小熊猫”、”喜欢”、”吃”,现在正在计算第四个 Token 应该是什么。
生成 Q、K、V:对每个 Token 的向量做 3 次线性变换(矩阵乘法),得到三个向量:
- Q(Query,查询):”我想找什么信息?”
- K(Key,键):”我提供什么信息?”
- V(Value,值):”我实际包含什么内容?”
计算相似度:用当前步骤生成的 Q(基于已生成的”吃”的向量)和前三个 Token 的 K 做点积,得到一组分数。分数越高说明越相关——“吃”的关联度最高(因为接下来要确定”吃什么”),”小熊猫”也有一定关联(因为在描述”谁”在吃)。
归一化(Softmax):把分数变成百分比(权重),所有权重加起来等于 1。
加权求和:用这些权重对前三个 Token 的 V 做加权求和,得到一个融合了上下文信息的向量。这个向量最终会帮助模型判断:接下来的词,”苹果”的得分远高于 “木头”、”香蕉”、”葡萄”——因为训练时模型见过无数”小熊猫喜欢吃苹果”的类似模式,这些模式已编码在权重中。所以模型预测出”苹果”的概率最高。
直观类比:Q 是”我在找什么信息”,K 是”我身上贴了什么标签”,V 是”我实际说了什么”。注意力 = 用 Q 扫过所有标签,找到匹配的,读取对应内容。
为什么 KV 可以缓存?
大语言模型使用因果注意力(Causal Attention):每个 Token 只能看到它前面的 Token,不能看到后面的。这意味着:
- 生成第 1 个 Token 后,它的 K₁、V₁ 就确定了
- 生成第 2 个 Token 时,需要用到 K₁、V₁,但 K₁、V₁ 不会再变
- 生成第 N 个 Token 时,前 N-1 个 Token 的 K、V 完全不变
所以可以把前 N-1 个 Token 的 K、V 存起来(就是后面会讲到的 KV Cache),第 N 轮只需:
- 对新输入的 Token 计算 Q、K、V(算力消耗大)
- 用新的 Q 和缓存中的所有 K、V 进行注意力计算(算力消耗相对小)
算力消耗的大致关系
- 生成 K、V:需要完整走过矩阵乘法,计算量大
- 用已有 K、V 进行注意力计算:K、V 无需重新生成,但仍需参与注意力矩阵运算,计算量较小
- 前馈(Feed-Forward):不受缓存影响,新 Token 仍需完全计算
这就是为什么 Chapter 2 会讲到的缓存命中不是免费(仍需注意力计算 + 前馈),但远比重新生成 KV 便宜。
多模态模型:升级函数
最初的纯文本模型只能处理文字,而多模态模型扩展了输入输出的范围:
| 类型 | 输入 | 输出 | 举例 |
|---|---|---|---|
| 纯文本模型 | 文本 | 文本 | Minimax M2.5,GLM-5 |
| 输入多模态 | 文本、图像(+音视频) | 文本 | Kimi K2.5、Qwen3.5 |
| 输出多模态 | 文本 | 文本、图像(+音视频) | DALL·E |
| 全模态模型 | 文本、图像、音视频 | 文本、图像、音视频 | Seedance 2.0,Sora 2,Qwen3-Omni |
多模态模型并不是真的“看懂”图片和音视频,而是通过编码器将图片、音视频转换成向量,和文字向量放在同一个“向量空间”里计算。
开源策略
在2025年春节 Deepseek 爆火之后,大家或多或少地都从新闻中得知它是“开源”模型,但大语言模型的开源并不等价于软件开放代码,可以简单分为两类:
- 完全开源
这种模式或许才是大多数人理解的开源,不仅开放权重,还公开训练代码、数据处理、完整流程,支持其他研究人员从零复现。
- 开放权重
这是最常见的一类,他们会将训练好的模型参数发布到Hugging Face、Github等平台,供社区下载到本地运行或微调。
代表模型有:Deepseek,Qwen,Minimax,智谱,月之暗面Moonshot。
值得一提的是,这类开放权重模型的许可证并不统一:有些采用 MIT 及其衍生协议、Apache 2.0 这类宽松协议,有些则使用各家自定义许可。是否支持商用、是否需要报备或遵守额外条款,还是要以对应模型仓库附带的 License 为准。
另外,Deepseek 除了开放权重以外,还在技术报告中分享了大量训练细节,为开源社区提供了不少有力的论文。
补充:微调 (Fine-tuning)
如果你下载了开源模型(比如Deepseek),用自己的数据继续训练一小段时间,让模型更懂你的业务,这个过程叫微调。
微调后的模型仍然是你的私有模型,推理时不需要联网。
术语速览
Token:语言模型处理文本的基本单位。英文约 0.3 Token/字符,中文约 0.6 Token/字符。向量:把文字、图片、音视频转换成”高维坐标”,让 AI 能在数学空间里计算它们的相似性。意思相近的词,它们的向量在空间中的角度、模长更接近。权重:模型训练后的最终参数文件。概率模型:基于统计预测,而非逻辑推理。温度 (Temperature):调节概率分布”集中程度”的参数;低温更有确定性,高温更有创造力。注意力 (Attention):让每个 Token 看到其他所有 Token,决定哪些信息重要的机制。Q、K、V:注意力机制中的三类向量——查询(Q)、键(K)、值(V)。前馈 (Feed-Forward):注意力层之后,对每个 Token 独立做非线性变换的网络层。幻觉:模型生成看似合理但事实错误的内容。上下文窗口 (Context Window):模型一次能处理的最大 Token 数(如 200K、1M)。
Chapter 2:输入、输出与记忆
这一章解释 AI 怎么”记住”你说过的话——从消息怎么在客户端和后端之间流转,到上下文如何在每轮对话中传递,再到缓存如何降低推理成本。
消息流转路径:客户端 → 业务后端(处理业务逻辑) → 模型服务(纯推理) → 业务后端 → 客户端
概念说明
- 客户端(Client):我们使用的Web UI、App(比如 Deepseek,千问,豆包)、其它AI终端(比如Claude Code),以及自己编写的会调用API的程序(比如沉浸式翻译自定义AI模型)。
- 业务后端(Backend):提供API服务的平台(如 DeepSeek 后端服务器),负责用户认证、计费、会话管理、上下文组装(会在本章后续讲解)等业务逻辑。
- 模型服务:实际运行大模型推理的GPU集群,它本身无状态(Stateless)(不关心是哪个用户发送的消息),只负责推理。
调用路径:
1 | 你的客户端 → [API请求] → 业务后端 → [格式化输入] → 模型服务 → [生成回复] → 业务后端 → [API响应] → 你的客户端 |
补充:
- 业务后端会负责将你发送的消息列表(如
[{“role”: “user”, “content”: “你好”}])按照模型要求的模板(例如添加特殊token、系统提示词)转换成模型能理解的输入格式。 - 模型服务返回原始输出后,业务后端可能进行后处理(如内容审核、格式封装),再返回给你。
记忆是外挂的数据库文本,压缩是早期对话的摘要替换,两者都是为了在有限窗口内提供更连贯的体验。
会话内记忆
下图展示了第四轮对话时的数据流向
sequenceDiagram
participant 用户
participant 前端
participant 后端
participant 模型
用户->>前端: 输入第4轮提示词
activate 前端
前端->>后端: 提示词+前3轮对话历史
activate 后端
后端->>后端: 组装完整提示词
(System + History + New Prompt)
后端->>模型: 流式请求(携带完整提示词)
activate 模型
loop 逐字生成
模型-->>后端: 流式响应(一个 Token)
后端-->>前端: 转发 Token
前端-->>用户: 逐字显示(打字机效果)
end
deactivate 模型
deactivate 后端
deactivate 前端
细节解释
上下文(Context)是怎么“记忆”的?
模型本身没有记忆。每轮对话,后端都会把之前的问答历史 + 当前问题打包成一个长文本,一起发给模型。就像你每次聊天前,先把之前的聊天记录读一遍,再回答新问题。为什么 AI 看起来在“打字”?(流式输出)
- 模型生成文本是一个一个 Token 预测的,不是先想好全文再输出。
- 后端采用 Stream 模式:每生成一个 Token 就立刻返回给前端,前端收到就显示一个。
- 效果:用户感觉 AI 在“边想边写”,体验更自然,等待焦虑也降低了。
跨会话记忆
- 实现方式:后端数据库存储用户的长期信息(如偏好、专业、关键事实),每次请求时,后端将这些信息拼接到提示词的开头,作为“记忆”提供给模型。
- 特点:记忆是显式插入的文本,用户可以查看/编辑/删除;模型本身不存储任何用户信息。
上下文压缩
各个大模型都有上下文窗口(Context Window),也就是模型推理时能输入的最多Token数量。
但是,随着同一会话中轮数增多,后续对话再附上系统提示词和前文的时候,很可能会超过模型支持的上下文窗口。
以前这种时候往往只能新开一个会话,但是现在有些客户端(比如Claude Code)支持上下文压缩(Compact)。
除了手动压缩以外,当对话接近上下文窗口上限时,后端会自动进行压缩。
- 目标:在长对话中,避免超出模型的上下文窗口限制,同时尽量保留早期重要信息。
- 实现流程(以窗口阈值触发为例):
- 监控:后端监控当前会话累积的token数,当达到预设阈值(如窗口的80%)时,触发压缩。
- 摘要生成:后端将最早的若干轮对话(例如前50%的token)发送给模型(或专门的摘要模型),请求生成一段简短摘要。
- 替换存储:用生成的摘要替换掉原始对话历史中的对应部分,存入会话数据库。
- 后续请求:下次组装提示词时,使用“摘要 + 近期原文”的结构,总token数显著降低,同时保留了核心信息。
整个压缩过程是异步执行的,后端在后台完成,不打断用户操作。
提示词缓存 (Prompt Caching)
缓存本质上是一个工程优化问题:既然每轮推理都要把没变过的历史消息重新算一遍,为什么不把中间结果存起来?
问题在哪?
回顾本章开头的流程:第 N 轮对话时,后端会把「前 N-1 轮的完整对话 + 第 N 轮的新问题」打包发给模型。
这意味着前 N-1 轮的内容每一轮都要被模型重新计算一次。如果这些内容有 100 万 Token,就等于每轮都在花算力重复算同样的东西。
缓存怎么工作?
模型推理的过程会产生中间状态——可以理解为模型在「阅读」你的历史消息时,每一层神经网络计算出的向量 Key-Value。
提示词缓存的做法很简单:
1 | 第 1 轮:计算所有输入 → 生成输出 → 保存所有输入对应的 KV 向量 |
每一轮真正需要从零计算的,只有新增的那一小部分,历史部分直接读缓存,跳过了重复的 KV 计算,从而节省算力和时间。
举个例子:一次对话里总共消耗了 166 万 Token,其中 154 万命中了缓存——也就是说,这 154 万 Token 的历史内容不需要重新计算,只有约 12 万 Token 的新增部分需要从头推理。
这和「缓存别人问过的答案」不一样
这里容易产生误解:提示词缓存不是把别人问过的问题的答案存起来,下次直接复制粘贴。
它存的是同一个会话内、你的历史消息经过模型计算后产生的中间向量,用于加速你自己后面的推理。你的缓存不会被共享给其他用户。
缓存的定价逻辑
为什么缓存命中也要收费? 缓存命中的意思是跳过了 KV 向量的重复生成,但这些向量仍然要参与后续每一层的注意力计算(Attention)。也就是说,模型不需要”从头写一遍 KV”,但每一层推理时仍然需要”对着已有的 K、V 进行注意力计算”,这个过程同样消耗算力。
所以缓存命中不是免费,而是大幅打折:省掉了生成 KV 的计算,但保留了使用 KV 的计算。
不同厂商的折扣力度差异很大:
- DeepSeek(V4 Flash):新输入 ¥1/百万 Token,缓存命中 ¥0.02/百万 Token(仅 2%),不额外收缓存创建费。
- Anthropic(Opus 4.7):基础输入 $5/百万 Token,缓存命中 $0.50/百万 Token(10%),且对缓存写入单独收费($6.25~$10)。
- OpenAI(GPT-5.5):输入 $5/百万 Token,缓存命中 $0.50/百万 Token(10%),不收创建费。
另一个差异是缓存有效期。 缓存不是永久的,一旦过期,下一条消息被视为全新建入,按原价计费。DeepSeek 默认启用缓存,有效期数小时;Anthropic 默认仅 5 分钟(1 小时需额外付费),也就是说在 Claude Code 里超过 5 分钟不交互,下一次就是一次完整的全新计算。
总结:长对话场景下,缓存策略直接决定了推理成本。缓存命中率越高、有效期越长、额外费用越少,用户的实际花费就越低。
补充说明
- 缓存只匹配输入的前缀部分,输出仍然通过实时推理生成,受 temperature 等参数影响。用缓存不会改变输出质量——只是更快、更便宜。
- 缓存系统通常是”尽力而为”,不保证 100% 命中。构建耗时在秒级,不再使用后会自动清空。
术语速览
API:应用程序接口,客户端和后端之间的通信协议无状态 (Stateless):模型不记住任何历史,每次都是全新开始对话模板 (Chat Template):将结构化消息格式化为模型输入字符串的规则流式输出 (Streaming):模型逐 Token 生成,后端实时转发,看起来像 AI 在打字。跨会话记忆:不同对话之间共享的用户信息异步操作:后台悄悄进行,不打断用户提示词组装 (Prompt Assembly):把记忆、历史、问题拼成一段文本提示词缓存 (Prompt Caching):将历史消息的 KV 中间向量保存下来,避免重复计算,显著降低推理成本
Chapter 3:从对话到工作——Agent
大语言模型本身并不能操作工具,因而有了Agent;Agent的能力不足,因而有了MCP、Skills。
为什么需要 Agent?
前面几章我们介绍了大语言模型的基本原理:它会根据输入预测下一个 Token。
换句话说,AI 一直在做”阅读理解”——你给它一段文字,它预测下一段文字。
但现在的 AI 产品(比如Qwen)往往能帮你搜索网页,执行代码(比如处理一些计算),深度研究之后生成PDF、PPT,以及不少其他功能。
这些功能的基础是依赖 Agent 这个中间层来实现的。
Agent 的核心概念
Agent = 能自主规划步骤、调用工具、自我纠错的程序。
涉及自主性的部分由大语言模型提供支持,涉及使用工具的部分由Agent程序操作。
你可以把 Agent 想象成一个”智能实习生“:
- 用户:领导,负责下达指令。
- Agent 容器:实习生本人,它是一个运行在云端或本地的程序,负责统筹全局。
- 大模型:实习生的”大脑”,负责理解意图、规划步骤、生成回复,但它没有手,不能直接操作电脑。
- MCP/Skill:实习生的”双手”和”工具包”,装在 Agent 容器内部,负责具体的搜索、文件读写、代码执行。
架构与数据流向
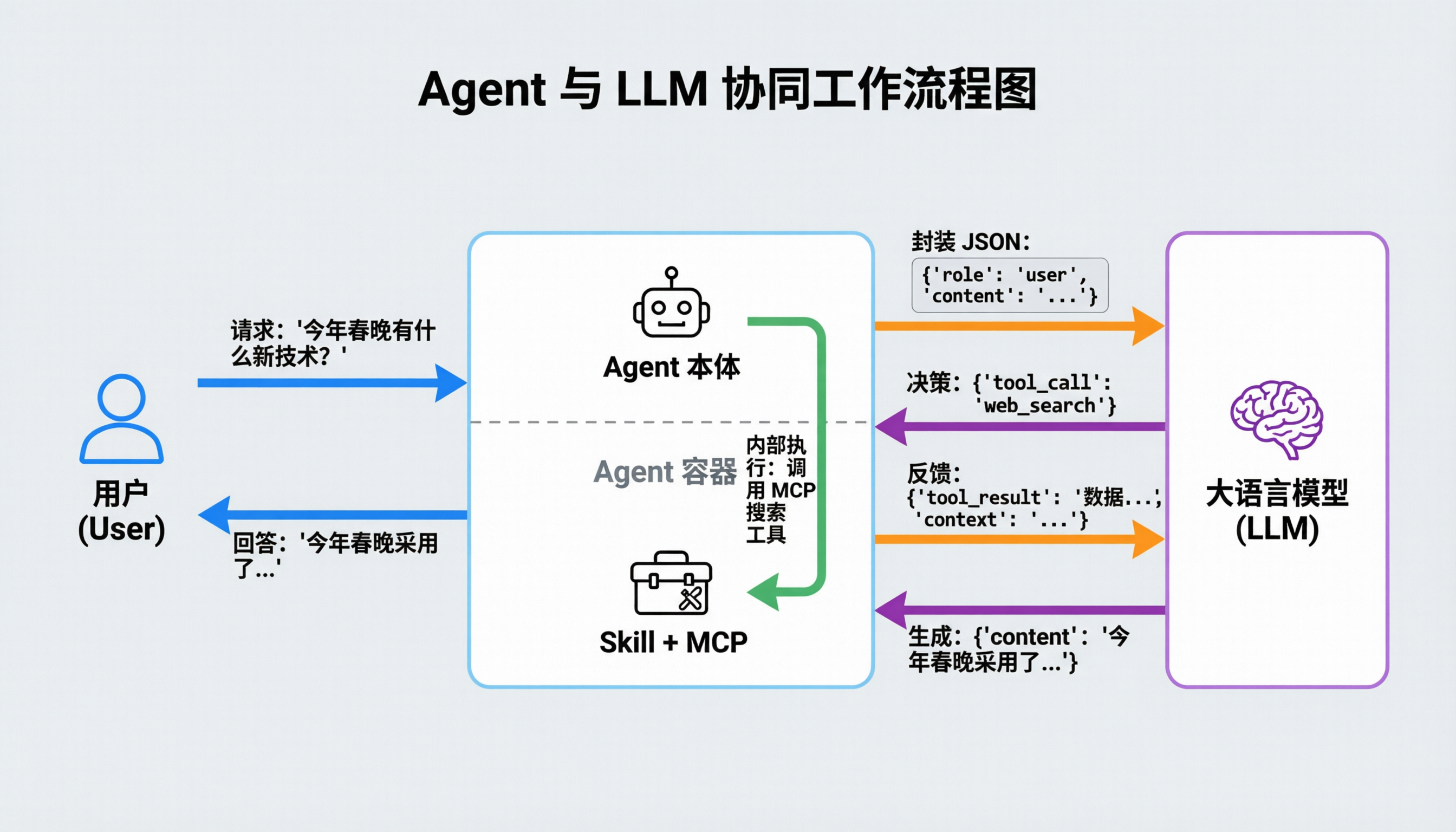
流程拆解
整个交互过程并非简单的”一问一答”,而是一个闭环的控制流:
- 请求输入:用户发送自然语言指令(例如:”今年春晚有什么新技术?”)。
- 封装 JSON:Agent 容器将指令打包成标准的 JSON 格式
({"role": "user", "content": "..."}),发送给大模型。 - 决策返回:大模型分析任务,发现需要外部数据,返回工具调用指令
({"tool_call": "web_search"})。 - 内部执行:关键步骤。Agent 容器接收到指令后,在本地调用下方的 MCP 或 Skill 模块执行搜索。这一步大模型不参与,数据也不出本地。
- 结果反馈:Agent 将搜索结果 与 历史消息(上下文)再次封装成 JSON
({"tool_result": "数据...", "context": "..."}),反馈给大模型。 - 生成回答:大模型结合用户最初的问题和搜索到的结果,进行推理,生成最终答案。
- 交付用户:Agent 将大模型生成的内容渲染后展示给用户。
用户视角的”一轮对话”,背后可能是 Agent 和大模型的”多轮协作”。
每一次工具调用,都是一次新的请求 - 响应循环。
核心概念:Function Calling
Function Calling 是一种”约定好的格式”,让大模型能用结构化语言说:”我需要调用 XX 工具,参数是 YY”。
类比:就像实习生写请假条,有固定模板(姓名/事由/天数),HR 一看就懂。
在技术实现上,这是 Agent 与大模型交流的规范。大模型不直接执行代码,而是输出符合特定格式的文本,由 Agent 解析并执行。
进阶概念:MCP 与 Skill
在 Agent 容器的下半部分,通常承载着具体的能力扩展。
MCP(Model Context Protocol)
MCP = Agent 调用外部工具的”通用接口协议”。
有了它,Agent 不用为每个工具写一套代码,像 USB 接口一样”即插即用”。
Skill(技能包)
Skill 是预验证的 AI 能力扩展包,核心是
skill.md文档。
它的优势是:开箱即用、减少 AI 现场编码的错误率。对于复杂任务,预先定义好的 Skill 比让大模型现场写代码更稳定。
Chat vs Agent
| 能力 | 客户端对话 | 智能体 |
|---|---|---|
| 能联网搜索 | ❌(除非模型自带) | ✅(通过工具) |
| 能操作文件 | ❌ | ✅ |
| 能执行代码 | ❌ | ✅(沙箱环境) |
| 适合任务 | 问答、创作、分析 | 规划、执行、自动化 |
| 架构 | 大模型 | 大模型 + Agent 容器(内含工具) |
术语速览
Function Calling:大模型与 Agent 之间的结构化交互约定。大模型输出”我需要调用 XX 工具,参数是 YY”,由 Agent 解析并执行。编排 (Orchestration):Agent 对任务步骤、工具调度及异常处理的管理逻辑。中间件 (Middleware):位于用户与模型之间,负责协议转换、流程控制与数据过滤。序列化 (Serialization):将程序对象或自然语言转换为 JSON 等约定格式的过程。确定性 (Determinism):相比模型生成的概率性,工具执行结果具有可复现性和准确性。